
Introduction
So far in the book, we have seen how Data Oriented Programming (DO) deals with requests that query information about the system, leveraging the representation of the whole system data as a single nested hash map.
In this chapter, we illustrate how DO deals with mutations, i.e. requests that change the system state. Mutations are inherently more complex than queries, especially in a concurrent system where mutations could conflict.
DO reduces significantly the complexity of mutations, by constraining the hash map that represents the system data to be immutable. We will see that in virtue of the immutability of the data, the code for a mutation is as efficient as the code for a query and we benefit from the same power of expression and flexibility as with queries.
DO manages concurrency using a lock free strategy called Optimistic Concurrency Control, that leads to high throughput of queries and mutations. The mutation logic is split into two distinct phases:
-
The Calculation phase where we compute what would be the next state of the system if only this mutation were executed.
-
The Commit phase where we update the state of the system taking into account possible concurrent mutations.
The code in both phases is made efficient in terms of memory and computation by ensuring that the data is immutable: Instead of mutating data in place, we create a new version of the data, leveraging a structural sharing algorithm. As a consequence, the computation done in the Calculation phase is efficient and the comparison between two versions of the data for conflict resolution in the Commit phase is super fast.
Optimistic Concurrency Control
Optimistic Concurrency Control with immutable data is super efficient.
In DO, we manage different versions of the system data. At a specific point in time, the state of the system refers to a version of the system data. Each time a mutation is executed, we move forward the reference.
The data is immutable but the state reference is mutable.


Updating the state of the system is done inside a commit phase. The commit phase is responsible for reconciling concurrent mutations when they don’t conflict or aborting the mutation.
Structural sharing
Structural sharing allows to efficiently create new versions of immutable data. In DO, we leverage structural sharing in the calculation phase of a mutation to compute the next state of the system based of the current state of the system. Inside the calculation phase, we don’t have to deal with any concurrency control: this is delayed to the commit phase. As a consequence, the code involved in the calculation phase of a mutation remains stateless and is as simple as the code of a query.
Let’s take a simple example from our library system: a library with no users and a catalog with a single book: Watchmen.
var library = {
"name": "The smallest library on earth",
"address": "Here and now",
"catalog": {
"booksByIsbn": {
"978-1779501127": {
"isbn": "978-1779501127",
"title": "Watchmen",
"publicationYear": 1987,
"authorIds": ["alan-moore", "dave-gibbons"],
"bookItems": [
{
"id": "book-item-1",
"rackId": "rack-17",
"isLent": true
}
]
}
},
"authorsById": {
"alan-moore": {
"name": "Alan Moore",
"bookIsbns": ["978-1779501127"]
},
"dave-gibbons": {
"name": "Dave Gibbons",
"bookIsbns": ["978-1779501127"]
}
}
},
"userManagement": {
// omitted for now
}
}Imagine that we want to modify the value of a field in a book in the catalog, for instance the publication year of Watchmen.
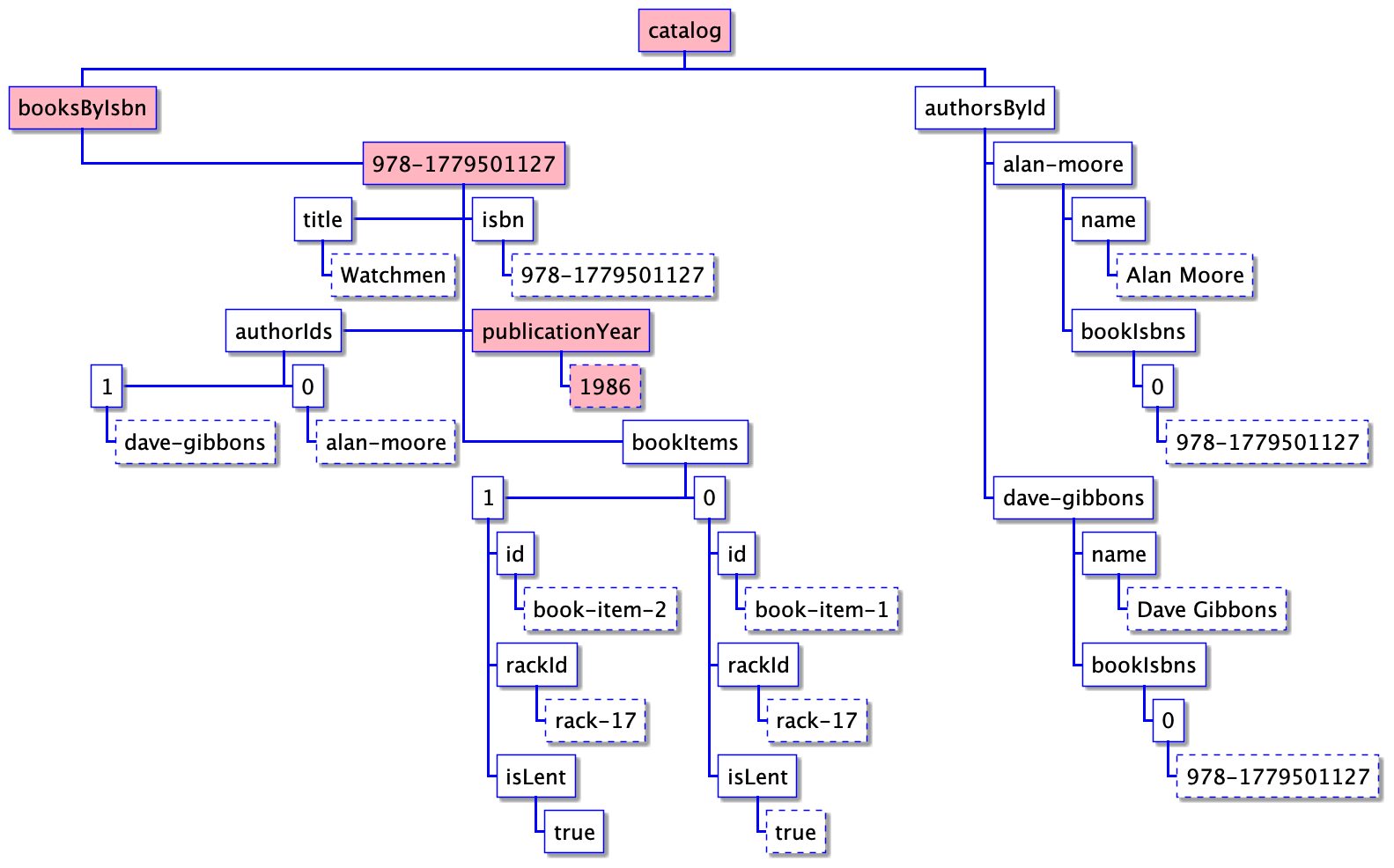
The information path for Watchmen publication year is: ["catalog", "booksByIsbn", "978-1779501127", "publicationYear"].
We are going to use the immutable function _.set() provided by Lodash.
By default Lodash functions are not immutable. In order to use a immutable version of the functions, we need to use Lodash FP module (Functional Programming), as it is explained in the Lodash FP guide.[1]. With this piece of code the signature of the immutable functions is exactly the same as the mutable functions.
_ = fp.convert({
"cap": false,
"curry": false,
"fixed": false,
"immutable": true,
"rearg": false
});Here is how we write code that creates a version of the library data where the publication year of Watchmen is updated to 1986, with the immutable function _.set() provided by Lodash.
var nextLibrary = _.set(library, ["catalog", "booksByIsbn",
"978-1779501127", "publicationYear"],
1986);In the new version of the library, the publication year of Watchmen is 1986
_.get(nextLibrary, ["catalog", "booksByIsbn",
"978-1779501127", "publicationYear"]);However in the previous version of the library, the publication year of Watchmen is still 1987
_.get(library, ["catalog", "booksByIsbn",
"978-1779501127", "publicationYear"]);A function is said to be immutable when instead of mutating the data, it creates a new version of the data without changing the data it receives. The immutable functions provided by Lodash are efficient because they use structural sharing.
Here is an illustration of how structural sharing works.
When you use an immutable function to create a new version of the Library where the publication year of Watchmen is set to 1986 (instead of 1987), it creates a fresh Library hash map that recursively uses the parts of the current Library that are common between the two versions instead of deeply copying them. This technique is called: structural sharing.
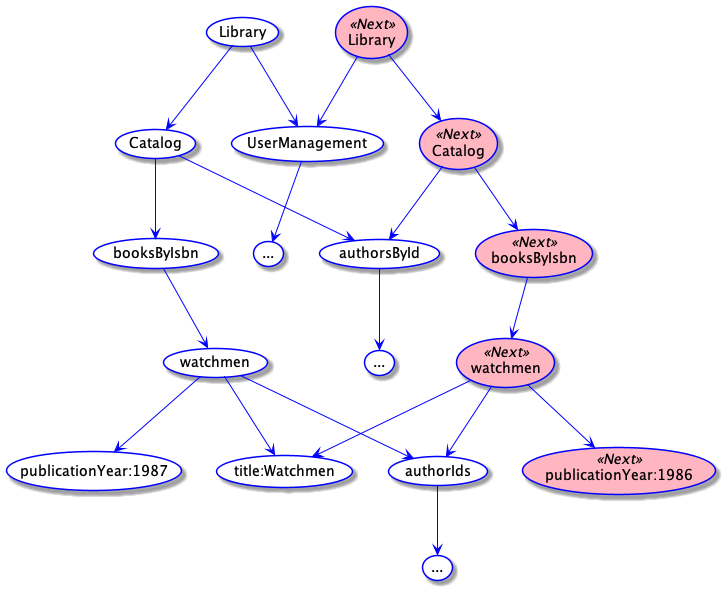
The next version of the Library, uses the same UserManagement hash map as the old one. The Catalog inside the next Library uses the same authorsById as the current Catalog. The Watchmen Book record inside the next Catalog uses all the fields of the current Book except for the publicationYear field.
As you can see by yourself, in nextLibrary the authorsById node is the exact same reference as in library
_.get(nextLibrary, ["catalog", "authorsById"]) == _.get(library, ["catalog", "authorsById"])We will see in a moment how we leverage this sharing of references to make the commit phase efficient.
Structural sharing provides an efficient way (both memory and computation) to create a new version of the data by recursively sharing the parts that don’t need to change.
Persistent data structures
Persistent data structures ensure the immutability of the data at the level of the data structure while immutable functions provide the immutability of the data at the level of the functions.
The way data is organized inside persistent data structures make them more efficient than immutable functions.
There are libraries providing persistent data structures in many languages: Immutable.js in JavaScript,[2] Paguro in Java,[3] Immutable Collections in C#,[4] Pyrsistent in Python,[5] and Hamster in Ruby.[6]
The drawback of persistent data structures is that they are not native which means that working with them require conversion from native to persistent and from persistent to native.
That’s one of the reasons why I love Clojure: the native data structures of the language are immutable!
The reconciliation algorithm
In a production system, multiple mutations run concurrently. Before updating the state, we need to reconcile.
Reconciliation between possible concurrent mutations is quite similar to what could happen in git when you push your changes to a branch and you discover that meanwhile the branch has moved forward because another developer has pushed her code to the branch.
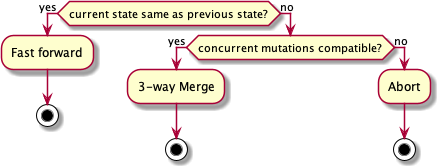
Like in git, there are three possibilities to reconcile between possible concurrent mutations: fast forward, 3-way merge or abort.
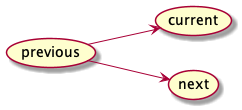
When the Commit phase of a mutation starts, we have 3 versions of the system state:
-
previous- the version on which the Calculation phase based its computation -
current- the current version -
next- the version returned by the Calculation phase
If we are in a situation where the current state is the same as the previous state, it means that no mutations run concurrently. Therefore, like in git, we can safely fast forward and update the state of the system with the next version.
If the state has not remained the same, it means that mutations have run concurrently. We have to check for conflicts in a way similar to the 3-way merge used by git. The difference is that instead of comparing lines, we compare fields of the system hash map.
We calculate the data diff between previous and next and between previous and current. If the two diffs are distinct, then there is no conflict between the mutations that have run concurrently. We can safely merge the changes from previous to next into current.

previous and next and we apply it to currentAnd if there is a conflict, we abort the mutation.
In a user facing system, conflicting concurrent mutations are fairly rare: that’s why it’s OK to abort and let the user run the mutation again.
The implementation of the Commit phase
The code for the Commit phase is made of 3 classes:
-
System, a stateful class that implements the mutations -
SystemDataa singleton stateful class -
SystemConsistency, a stateless class that provides conflict resolution logic
Let’s start with the System class and how it implements the addMember mutation.
class System {
addMember(member) {
var librarySnapshot = SystemData.get();
var nextLibary = Library.addMember(librarySnapshot, member);
SystemData.commit(librarySnapshot, nextLibrary);
}
}Here is the code for the SystemData class: It is the only stateful class in a DO system!
class SystemData {
systemData;
get() {
return this.systemData;
}
set(_systemData) {
this.systemData = _systemData;
}
commit(previous, next) {
this.systemData = SystemConsistency.reconcile(this.systemData,
previous,
next);
}
}
window.SystemData = SystemData;And how does SystemConsistency do the reconciliation?
The SystemConsistency class starts the reconciliation process by comparing previous and current. If they are the same, then we fast-forward and return next.
class SystemConsistency {
static threeWayMerge(current, previous, next) {
var previousToCurrent = DataDiff.diff(previous, current);
var previousToNext = DataDiff.diff(previous, next);
if(DataDiff.isEmptyIntersection(previousToCurrent, previousToNext)) {
return _.merge(current, previousToNext);
}
throw "Conflicting concurrent mutations.";
}
static reconcile(current, previous, next) {
if(current == previous) {
// fast forward
return next;
}
return SystemConsistency.threeWayMerge(current,
previous,
next);
}
}
window.SystemConsistency = SystemConsistency;The reconciliation algorithm relies on DataDiff class that implements the computation of a data diff between two hash maps and the detection of empty intersection. The internals of the DataDiff class are revealed in Computing the data diff between two hash maps.
Have you noticed that we compare previous and current by reference instead of comparing them recursively by value? That’s another benefit of immutable data: when the data is not mutated, it is safe to compare references and if they are the same, we know for sure that the data is the same.
Now, to the implementation of the 3-way merge algorithm.
When previous differs from current, it means that concurrent mutations have run. In order to determine whether there is a conflict or not, we calculate the two diffs: previousToCurrent and previousToNext. If the intersection between the two diffs is empty, it means there is not conflict. We merge previousToNext into current.
You may have noticed that think the code for the Consistency class is not thread safe! If there is a context switch between checking whether the system has changed in the Consistency class and the updating of the state in SystemData class, a mutation might override the changes of a previous mutation.
The code works fine in a single threaded environment like JavaScript where concurrency is handled via an event loop. However in a multi threaded environment, the code needs to be refined a bit and use atoms to be thread safe.
Some examples
Let’s make the reconciliation algorithm more concrete by giving an example of a reconciliation between non-conflicting concurrent mutations.
A mutation that updates the publication year of a book will not conflict with a mutation that updates the title of the same book. A reconciliation will result in a system state where both the title and the publication year are updated.
var previous = library;
var next = _.set(library,
["catalog", "booksByIsbn", "978-1779501127", "publicationYear"],
1986);
var current = _.set(library,
["catalog", "booksByIsbn", "978-1779501127", "title"],
"The Watchmen");The diff between previous and current is a nested map with a single field that holds the updated title.
DataDiff.diff(previous, current);And the diff between previous and next is also made of a single field for the updated publication year.
DataDiff.diff(previous, next);Now you see clearly how the code detects that the two mutations don’t conflict: the two nested maps have no leaf in common!
The result of the reconciliation is a library where both the title and the publication year are updated.
_.get(SystemConsistency.reconcile(current, previous, next),
"catalog");And here is an example of conflicting mutations: Two mutations that update the publication year of the same book will conflict.
var previous2 = library;
var next2 = _.set(library,
["catalog", "booksByIsbn", "978-1779501127", "publicationYear"],
1984);
var current2 = _.set(library,
["catalog", "booksByIsbn", "978-1779501127", "publicationYear"],
1986);Here the two diffs contain the same field.
DataDiff.diff(previous2, current2);DataDiff.diff(previous2, next2);In that case, the reconciliation will fail.
Wrapping up
In this chapter, we have explored how DO manages state with Optimistic Concurrency Control, where the mutation logic is split into Calculation and Commit phases.
During the Calculation phase, the data is manipulated with immutable functions that leverage structural sharing to create efficiently (memory and computation) a new version of the data where the data that is common between the two versions is shared.
Conflict resolution between concurrent mutations occur in the Commit phase. The code for the commit phase is common to all the mutations. The code that implements conflict detection in the commit phase is efficient in virtue of structural sharing.