
The plan
Our journey is made of 4 stations - each of them depending on the previous ones:
- The tokenizer (aka “Lexical Analysis”): converting an input code - in
LISPsyntax - into an array of tokens. - The parser (aka “Syntactic Analysis”): transforming an array of tokens into an Abstract Syntax Tree (AST).
- The emitter (aka “Code Generation”): string-ifying an AST into
C-like code. - The compiler (aka “You made it”): combining all the pieces together.
(The interactive code snippets are powered by a tool of mine named KLIPSE.)
The parser
Our parser is going to take an array of tokens and turn it into an Abstract Syntax Tree (an AST).
An array like this:
[{ type: 'paren', value: '(' }, ...]
should become a tree like that:
{ type: 'Program', body: [...] }

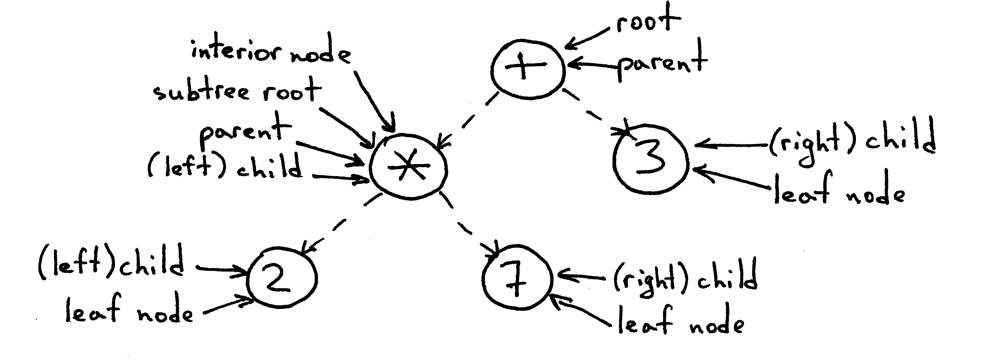
Code organization
Our code is going to be organized this way:
parseProgram: receives an array of tokens and return aProgramnode with abody- callingparseTokenparseToken: receives a single token and according to its type calls eitherparseNumber,parseStringorparseExpressionparseNumber: receives a token and returns aNumbernodeparseStringreceives a token and returns aStringnodeparseExpression: receives a token and returns anExpressionnode - callingparseTokenrecursively
Each parser (except parseProgram) returns an array with:
- the updated current position
- the parsed node
Number and String parsers
Number and String parsing is really straightforward:
parseNumber = (tokens, current) => [current + 1,
{type: 'NumberLiteral',
value: tokens[current].value,
}]
parseNumber([{
"type": "number",
"value": "42",
}], 0)
parseString = (tokens, current) => [current + 1,
{type: 'StringLiteral',
value: tokens[current].value,
}]
parseString([{
"type": "string",
"value": "Hello World!",
}], 0)
Expression parsing
Parsing an expression is much trickier because expressions can be nested like (add 1 (subtract 3 2)).
No worries: javascript supports recursions!!!
The code of parseExpression is going to:
- Skip the first token - it is the opening parenthesis
- Create a base node with the type
CallExpression, and name from the current token - Recursivelly call
parseTokenuntil we encounter a closing parenthesis - Skip the last token - it is the closing parenthesis
Not so complicated. Right?
Here is the code:
parseExpression = (tokens, current) => {
let token = tokens[++current];
let node = {
type: 'CallExpression',
name: token.value,
params: [],
};
token = tokens[++current];
while (!(token.type === 'paren' && token.value ===')')) {
[current, param] = parseToken(tokens, current);
node.params.push(param);
token = tokens[current];
}
current++;
return [current, node];
}
Unfortunately, we cannot test parseExpression until we implement parseToken (because of the recursion)…
Token parsing
The code of parseToken is really simple, calls the parser that corresponds to the token type:
parseToken = (tokens, current) => {
let token = tokens[current];
if (token.type === 'number') {
return parseNumber(tokens, current);
}
if (token.type === 'string') {
return parseString(tokens, current);
}
if (token.type === 'paren' && token.value === '(') {
return parseExpression(tokens, current);
}
throw new TypeError(token.type);
}
Let’s test parseExpression - first with a simple expression:
const tokens = [
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
]
parseExpression(tokens, 0)
And now - with a nested expression:
const tokens = [
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]
parseExpression(tokens, 3)
Program parsing
A program is composed by a series of expressions, therefore parseProgram is going to call parseToken until all the tokens are parsed:
function parseProgram(tokens) {
let current = 0;
let ast = {
type: 'Program',
body: [],
};
let node = null;
while (current < tokens.length) {
[current, node] = parseToken(tokens, current);
ast.body.push(node);
}
return ast;
}
Let’s give parseProgram a nickname:
parser = parseProgram
Let’s test parseProgram:
const tokens = [
{ type: 'paren', value: '(' },
{ type: 'name', value: 'print' },
{ type: 'string', value: 'Hello' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]
parseProgram(tokens, 0)
You did it! You have written a parser for our Lisp-like language…
Please take a short rest before moving towards Station #3: The emitter.