
Motivation
When we build an application that embraces data immutability, we handle changes in data by creating a new version of data instead of mutating data in place, without compromising on performance. There are various techniques to achieve data immutability in an efficient manner.
JavaScript data manipulation libraries like Ramda and Lodash FP provide an interesting implementation of structural sharing via a technique called path copying. The cool thing with path copying is that it works with native JavaScript objects.
After reading this article, you will:
- 😄 Be part of the few lucky JavaScript developers that clearly understand what is structural sharing
- 💻 Implement structural sharing in a few lines of JavaScript code
- ⚠️ Be aware of the limitation of path copying
- 🤗 Be motivated to read my book about Data-Oriented programming
Remark: This article assumes that you are already aware of the benefits of data immutability.
What is structural sharing?
Structural sharing provides an efficient way to share data between multiple versions of it, instead of copying the whole data.
It’s kind of similar to the way git manages multiple versions of your source code: git doesn’t copy all the files on each commit. Instead, the files that are not changed by a commit are shared with previous commits.
The same strategy could be applied with data. Let’s take as an example a map that represents the data of a library in a library management system. In this map, we have 4 fields:
name: a string for the name of the libraryaddress: a string for the address of the librarycatalog: a map with the book informationusers: a map for the user information
Here is an example of a tiny library, with two users and a single book:
var libraryData = {
"name": "The smallest library on earth",
"address": "Here and now",
"users": [
{"username": "user-1",
"password": "pass-1"},
{"username": "user-2",
"password": "pass-2"}
],
"catalog": {
"books": [
{
"title": "Watchmen",
"publicationYear": 1986,
"authors": [
{
"firstName": "Alan",
"lastName": "Moore"
},
{
"firstName": "Dave",
"lastName": "Gibbons"
}
]
}
]
}
}
Suppose we want to create a version of the library where the address field is modified. We can achieve that by shallow copying the original library and modify the address field, using Object.assign().
function set(obj, key, val) {
var copy = Object.assign({}, obj);
copy[key] = val;
return copy;
}
For fields whose values are strings, it works fine because strings are immutable in JavaScript. But what about fields whose values are maps? We don’t want changes made on one of version of the map to be reflected on the other versions of the map!
Like in git, we don’t want changes in a commit to affect files in a previous commit!
We could solve this challenge in a very naive way by deep copying the whole map when creating a new version of it. But of course, it would have a negative impact on the performance, both in terms of memory and CPU.
Another approach is to prevent data from being changed. When data is immutable, we don’t need to protect ourselves from the threat we just mentioned. It is safe to do a shallow copy of the data because immutable data never changes.
Data immutability could be guaranteed either by convention (and code reviews) or by the program itself. For example, JavaScript provides a way to prevent data from being changed, via Object.freeze(). Here is an implementation of a deep freeze, from MDN:
function deepFreeze(object) {
const propNames = Object.getOwnPropertyNames(object);
// Freeze properties before freezing self
for (const name of propNames) {
const value = object[name];
if (value && typeof value === "object") {
deepFreeze(value);
}
}
return Object.freeze(object);
}
That’s the essence of structural sharing:
- Make sure data is immutable
- Create new version of data via shallow copying
Here is a code snippet for a function called set() that implements structural sharing when the change occurs at the root of the map:
function shallowCopy(o) {
if(Array.isArray(o)) {
return Object.assign([], o);
}
return Object.assign({}, o);
}
function set(o, k, v) {
var copy = shallowCopy(o);
copy[k] = v;
return copy;
}
Creating a new version of data with a change at the root of a map is easy. Now, we are going to show how to handle changes at any nesting level in a map.
Implementation of path copying in JavaScript
Suppose we want to update the password of a user and see how to apply recursively our structural sharing strategy:
- Shallow copy
name,addressandcatalog. - Use a modified version of
users:- Shallow copy all users except
user-1 - Use a modified version of
user-1:- Shallow copy all the fields except
password - Modify
password
- Shallow copy all the fields except
- Shallow copy all users except
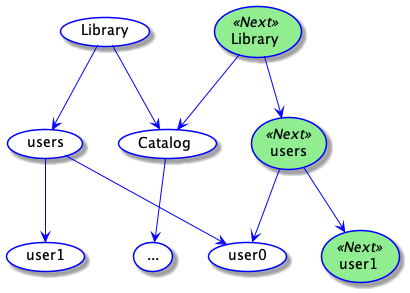
The code for it would look like this:
var nextUser = Object.assign({}, libraryData.users[1]);
nextUser.password = "new-pass-2";
var nextUsers = Object.assign([], libraryData.users);
nextUsers[1] = nextUser;
var nextLibraryData = Object.assign({}, libraryData);
nextLibraryData.users = nextUsers;
And now, let’s generalize this approach with a recursive functions. As we promised in the article title, here is an implementation of structural sharing in 7 lines of JavaScript code:
function setIn(m, [k, ...restOfPath], v) {
var modifiedNode = v;
if (restOfPath.length > 0) {
modifiedNode = setIn(m[k], restOfPath, v);
}
return set(m, k, modifiedNode);
}
Here is how we use setIn to modify the password of a user:
var libraryDataV1 = setIn(libraryData, ["users", 1, "password"], "new-pass-2");
libraryDataV1.users[1].password
Of course, the previous version is left unchanged:
libraryData.users[1].password
Efficiency of structural sharing
Path copying is usually efficient – both in terms of memory and computation – because most of the nodes in a nested map are copied by reference (shallow copy).
For example, the catalog map (that could be a huge object) is shared between the original library data and the new version of library data. They both use the same reference.
libraryDataV1.catalog === libraryData.catalog
Path copying works fine with deeply nested data where at each nesting level we don’t have too many elements. When we have many elements at some level, shallow copying might be an issue. Suppose we have a million user in our system, copying a million references each time we update the password of a user is not acceptable.
The same issue occurs with git if you have a folder with too many files.
In my book about Data-Oriented programming, I discuss techniques to overcome this limitation.
The book illustrate in details the benefits of building a software system based upon data immutability.